Hello
My name is Tomasz Dziopa and this is my space for scribbling thoughts.
Put your docker images on a diet
Why big = bad?
Large images are bad in two ways:
- they take up a lot of space on the disk. Docker daemon enforces an upper bound on the total size of images on your disk - if you rebuild the images frequently and they are large, you will end up cleaning up your cache very frequently.
- they take a lot of time to download. This is bad, because:
- not everyone has an unlimited broadband connection! It sucks when you have to download fat docker image using your cafe's shitty wifi or using your mobile plan allowance
- there are cases when bandwidth can become costly. If you host your images in a private repo at your cloud provider, it's quite likely that they'll charge you for egress bytes.
So - how big is it?
docker image list | grep <image name>
will list all available tags for your image with their uncompressed sizes. This is how much the image actually takes on your hard drive.
docker manifest inspect <image> | jq ".layers | map(.size) | add / 1024"
will output a single number: the total size in MB of compressed layers. This is how much needs to be downloaded over the network in case of layer cache misses (worst case).
Best practices
Generic advice is all about understanding how docker image layers work. In general, each layer contains only a set of differences from the previous layer. This applies to not only adding and updating files, but also removing.
In order to keep your keep your layer sizes small, only persist changes which are relevant to functioning of the final container. Do not persist: package manager caches, downloaded installers and tremporary artifacts.
Common strategy to solving this problem is chaining installing and cleanup commands as a single layer definition.
instead of doing this:
FROM ubuntu:20.04 # 66 MB
RUN apt update # 27 MB
RUN apt install -y curl libpq-dev # 16 MB
# total size: 109 MB
do:
FROM ubuntu:20.04 # 66 MB
# removing apt cache after successful installation of dependencies
RUN apt update \ # 16 MB
&& apt install -y curl libpq-dev \
&& rm -rf /var/lib/apt/lists/*
# total size: 82 MB
Another common approach to solving this problem is to use multi-stage build. Generally, the idea here is to perform some potentially heavy operations (e.g. compiling a binary from sources) in a separate layer, and then to copy just the resulting artifacts into new, "clean" layer. Example:
# Stage 1: build the Rust binary.
FROM rust:1.40 as builder
WORKDIR /usr/src/myapp
COPY . .
RUN cargo install --path .
# Stage 2: install runtime dependencies and copy the static binary into
a clean image
FROM debian:buster-slim
RUN apt-get update \
&& apt-get install -y extra-runtime-dependencies \
&& rm -rf /var/lib/apt/lists/*
COPY --from=builder /usr/local/cargo/bin/myapp /usr/local/bin/myapp
CMD ["myapp"]
Since every package manager has it's own arguments and best practices, the easiest way to manage this complexity is to use a tool which can find quick-wins in your Dockerfile definition. Open source hadolint analyzes your Dockerfile for common issues.
Removing cruft
If you've been developing with your Dockerfile for some time, there's a good chance you experimented with different libraries and dependencies, which often have the same purpose. The general advice here is: take a step back and analyze every dependency in your Dockerfile. Throw away each and every dependency which is not essential to the purpose of the image.
Another very effective approach at elliminating cruft is to examine the contents of the image layers. I cannot recommend enough dive CLI, which lets you look at the changes applied by each layer and hints at the largest and repeatedly modified files in the image.
By examining docker build trace you may also identify that you're installing GUI-specific packages (e.g. GNOME icons, extra fonts) which shouldn't be required for your console-only application. Good practice is to analyze the reverse dependencies of these packages and look for top-level packages which triggered the installation of the unexpected fonts. E.g. openjdk-11-jre package bundles suite of dependencies for developing UI apps. Some tips on debugging the issue:
- just try removing the suspicious system package. Package managers should resolve the unmet dependencies and suggest potential top-level offending package as scheduled for removal.
- use tools like
apt-rdepends <package>to see a flattened list of packages which depend on the<package>.
Base image choice
Choosing the base image is one of the very first decisions people make when creating new image. It's quite common that the choice is affected by e.g. some example image on github, or what's already being used among your colleagues or organization.
Changing the base image can be quite significant to the overall image, but sometimes it's definitely worth revisiting that. Here's a quick walthrough of common points for consideration:
- choosing a
-slimimage variant. Some distros (e.g. debian) offer a stripped-down version, with features which are redundant to most images removed. For non-interactive console applications, you usually do not need documentation and man pages. alpineimages -alpineis a container-optimized linux distribution, which uses it's own package manager (apk) and alternative implementation oflibc,musl. The final images are usually very small, although there are some limitations:- in case your application relies on
libc, you will need to recompile it formusl. - own package repository is sometimes lacking in comparison to
debianand the versions may not be updated as frequently - relatively small community support
- in case your application relies on
distrolessimages - the slimming down approach taken to extreme, with virtually all non-essential components (including shell!) of the operating system stripped out from debian images. Conceptually, the application and all it's dependencies should be copied into the distroless image from a previous image stage (see example Dockerfile, more usages in kubernetes)- could be a good choice if your application is statically linked or has a well-defined set of dependencies (think: limited set of shared libraries).
Image specialization
Common issue with rapidly evolving codebases is that the images are not specialized - image serves as a common execution environment for a very distinct use cases. For the purpose of this section, let's call these "furball" images.
Best practice is to identify the key use cases of the particular components and build dedicated images for these use cases. This way you can encourage better separation of concerns in your codebase.
Assuming all the images are retaining all their dependencies, in best case you will experience summed size of all specialized layers to be exactly the same as the "furball" image. But, the benefits are substantial:
- specialization may encourage deeper cleanup of the dependencies
- specialization may encourage bigger changes in the organization of the codebase, like factoring the code into components.
- running specialized workflow will require fetching way smaller image
- Since you usually don't work on all components at the same time, you'll experience significant improvement in quality of life - you'll be downloading just the dependencies used by your component!
Runtime tools
There were multiple attempts to minify the docker images by analyzing the runtime usage of files within the container. How this is supposed to work:
- spin up the container with a sidecar container tracking every access to a file inside the filesystem
- Perform actions on the running container covering all of the use cases of the image.
- Let the tool export the image containing just the files from the filesystem which were accessed in previous step.
The results of this workflow can be very good, although your results may vary depending on the use cases. Some points for consideration:
- the image is no longer a result of
docker build - the slimming down workflow may remove some files from the image which can affect the functionality of the image or it's security => how much do you trust the tool that the image is secure and correct?
- image may not be suitable for any other use case than the one used in the slimming down process. This may be a showstopper for the images used for experimentation.
Getting started with Natural Language Processing in Polish
There are countless tutorials on how to do NLP on the internet. Why would you care to read another one? Well, we will be looking into analysing Polish language, which is still rather underdeveloped in comparison to English.
Polish language is much more complex when compared to English language, as it contains 7 cases (deklinacja), 3 kinds (masculine, femenine, unspecified) and 11 different templates of verb conjugation, not to mention the exceptions [1] [2] [3]. English is rather simple: verb conjugation is easy, nouns pluralise easily, there are hardly any genders.
Corpus
For the sake of this analysis, we will look at collection of articles obtained (the nice word for scraped) from one of the leading right-wing news websites, wpolityce.pl.
 Sample article from the dataset.
Sample article from the dataset.
The articles were collected over a period of 15 days ending 10th June 2019, only articles linked from front page were collected. In total there are 1453 unique articles. I shall later publish my insights on collecting datasets from the wild.
Tokenizing
Tokens are the smallest unit of the language that's most commonly taken into account when doing text analysis. You may think of it as a word, which in most cases it is. Things get trickier in English with it's abbreviations like I'd or we've but Polish is much easier in this aspect.
„|Gazeta|Wyborcza|”|wielokrotnie|na| |swoich|łamach|wspierała|działania|Fundacji|Nie|lękajcie|się|Marka|Lisińskiego|.
Sample tokenization of a sentence from the corpus, tokens are delimited with vertical bars. Please note empty token between words na and swoich - it's a dirty whitespace, which we'll deal with shortly.
In Python, you can tokenize using either NLTK's nltk.tokenize package or spaCy's tokenizer using pretrained language models. I have used the latter with xx_ent_wiki_sm multilanguage model. In empirical analysis it appeared to split up the tokens in a plausible manner.
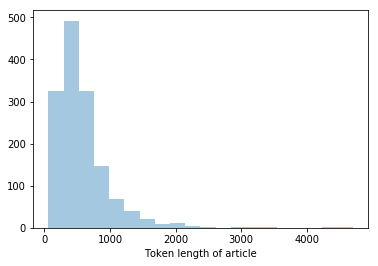
The distribution of numbers of tokens in an article: vertical axis shows number of articles falling into particular bucket, horizontal axis is the token lenght of article.
Quantitative analysis: corpus
Reading the entire dataset without any cleaning yields mediocre results. The resulting corpus contains:
- badly interpreted non-breaking space from latin1 encoding (
"\xa0") - whitespace-only tokens (
"\n","\n \n"and others) - punctuation, also in repeated non-ambiguous way (multiple quote chars, hyphen/minus used interchangeably)
- stopwords: common words that skew the word distribution but do not bring any value to the analysis.
Frequent words (unigrams)
| word | frequency |
|---|---|
| PiS | 1444 |
| proc | 1198 |
| wyborach | 835 |
| powiedział | 726 |
| PAP | 709 |
| PSL | 676 |
| r. | 653 |
| Polski | 652 |
| Polsce | 625 |
| Europejskiej | 601 |
Word cloud
The raw data above can be visualised using a word cloud. The idea is to represent the frequency of the word with it's relative size on the visualisation, framing it in visually attractive and appealing way.
You can find plenty of online generators that will easily let you tweak the shape, colors and fonts. Check out my wordcloud of 50 most common words from the corpus generated using generator from worditout.com

Concluding our unigram analysis, the most common topics were revolving around PiS (abbreviation used by the polish ruling party), elections (wyborach stands for elections, proc. is abbreviated percent).
Ngrams
Ngram is just a sequence of n consecutive tokens. For n=2 we also use word bigram. You can get the most frequent Ngrams (sequences of words of particilar length) using either nltk.ngrams or trivial custom code. For length 2-3 you are highly likely to fetch popular full names. Longer ngrams are likely to catch parts of frequently repeated sentences, like promos, ads and references.
Bigrams
As expected, we are catching frequent proper names of entities in the text. Below is a breakdown of 10 most frequent bigrams from the corpus:
| frequency | bigram | interpretation |
|---|---|---|
| 377 | Koalicji Europejskiej | political party |
| 348 | Parlamentu Europejskiego | name of institution |
| 322 | PAP EOT | source/author alias |
| 261 | 4 czerwca | important date discussed at the time |
| 223 | Koalicja Europejska | political party |
| 136 | Andrzej Duda | full name of President of Poland |
| 126 | Jarosław Kaczyński | full name of important politician |
| 126 | Jana Pawła | most likely: prefix from John Paul II |
| 125 | Pawła II | most likely: suffix from John Paul II |
Sixgrams
Longer ngrams expose frequent phrases used throughout the corpus. Polish has a lot of cases and persons, so this method is not of much help to find frequent phrases in the language itself; you are more likely to find repeated parts of sentences or adverts.
| frequency | sixgram |
|---|---|
| 61 | Kup nasze pismo w kiosku lub |
| 61 | nasze pismo w kiosku lub skorzystaj |
| 61 | pismo w kiosku lub skorzystaj z |
| 61 | w kiosku lub skorzystaj z bardzo |
| 61 | kiosku lub skorzystaj z bardzo wygodnej |
Clearly, there is an issue here. While doing our quantitative analysis our distributions and counts are skewed by the advert texts being present in most of the articles. Ideally we should factor these phrases out of our corpus, either at a stage of data collection (improving the parser to annotate/omit these phrase) or data preprocessing (something we're doing in this article).
Much better idea is to perform ngrams analysis on lemmatized text. This way you may mine more knowledge about the language, not just repeated phrases.
Morphological analysis
In the previous paragraph we saw that the different forms of the words will make learning about the language harder - we are capturing the information about the entire word, with the particular gender, tense and case. This becomes particularly disruptive in Polish.
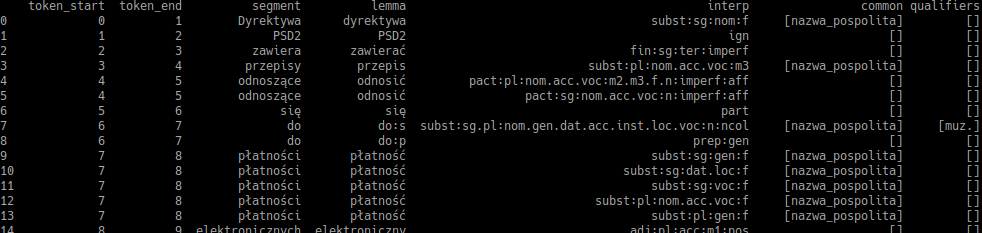
One potential solution is called morphological analysis. This is a process of mapping a word to all of it's potential dictionary base words (lexems). Sample lemmatization:
| Original word | Lemma tag | Lexem |
|---|---|---|
| Dyrektywa | dyrektywa | subst:sg:nom:f |
| PSD2 | PSD2 | ign |
| zawiera | zawierać | fin:sg:ter:imperf |
| przepisy | przepis | subst:pl:nom:m3 |
| odnoszące | odnosić | pact:sg:nom:n:imperf:aff |
| się | się | qub |
| do | do | prep:gen |
| płatności | płatność | subst:sg:gen:f |
| elektronicznych | elektroniczny | adj:pl:gen:m1:pos |
| realizowanych | realizować | ppas:pl:gen:m1:imperf:aff |
| wewnątrz | wewnątrz | adv:pos |
| Unii | unia | subst:sg:gen:f |
| Europejskiej | europejski | adj:sg:gen:f:pos |
| . | . | interp |
We will not be implementing this part from scratch, instead we can use resources from IPI PAN (Polish Academy of Science), specifically a tool called Morfeusz.
Morfeusz is a morphosyntactic analyzer which you can use to find all word lexems and the forms. The output will be slightly different than the table above: instead, for every input word Morfeusz will output all of it's possible dictionary forms.
Usage
I assume you are running either a recent Ubuntu or Fedora. After fetching the right version from Morfeusz download page do the following:
tar xzfv <path to archive>
sudo cp morfeusz/lib/libmorfeusz2.so /usr/lib/local
sudo chmod a+x /usr/lib/local/libmorfeusz2.so
sudo echo "/usr/local/lib" > /etc/ld.so.conf.d/local.conf
sudo ldconfig
Now we can download and install the python egg from morfeusz download page.
easy_install <path_to_downloaded_egg>
The best thing about the python package is that you can retrieve the result from the analyzer using just a couple of python lines:
import morfeusz2
m = morfeusz2.Morfeusz()
result = m.analyze("Ala ma kota, kot ma Alę.")
# the result is:
[(0, 1, ('Dyrektywa', 'dyrektywa', 'subst:sg:nom:f', ['nazwa_pospolita'], [])),
(1, 2, ('PSD2', 'PSD2', 'ign', [], [])),
(2, 3, ('zawiera', 'zawierać', 'fin:sg:ter:imperf', [], [])),
(3,
4,
('przepisy', 'przepis', 'subst:pl:nom.acc.voc:m3', ['nazwa_pospolita'], [])),
(4,
5,
('odnoszące',
'odnosić',
'pact:pl:nom.acc.voc:m2.m3.f.n:imperf:aff',
[],
[])),
(4, 5, ('odnoszące', 'odnosić', 'pact:sg:nom.acc.voc:n:imperf:aff', [], [])),
Putting it all in a pandas DataFrame is a trivial task as well:
import pandas as pd
colnames = ["token_start", "token_end", "segment", "lemma", "interp", "common", "qualifiers"]
df = pd.DataFrame.from_records([(elem[0], elem[1], *elem[2]) for elem in result], columns=colnames)
Helpful links on tackling Morfeusz:
Lemmatization
You have already seen the output of a lemmatizer at the beginning of previous section. In contrast to Morfeusz's output, this time we want to obtain a mapping for each word to it's most probable dictionary form.
In order to obtain direct tags instead of list of tags for each token, you will need to go deep into morphological taggers land. Your options are:
- WCRFT - actually having a working demo here. Requires some skill to get it to work, dependencies are non-trivial to put together,
- PANTERA - doesn't appear to be actively maintained
- Concraft - implemented in Haskell, looks to be the easiest one to get running
If you are just doing a casual analysis of text, you may want to consider outsourcing the whole tagging process to a RESTful API, like http://nlp.pwr.wroc.pl/redmine/projects/nlprest2/wiki/Asynapi.
You can easily reverse-engineer the exact calls to the API using Firefox/Chrome dev tools. This way you can find the correct values for the parameters.
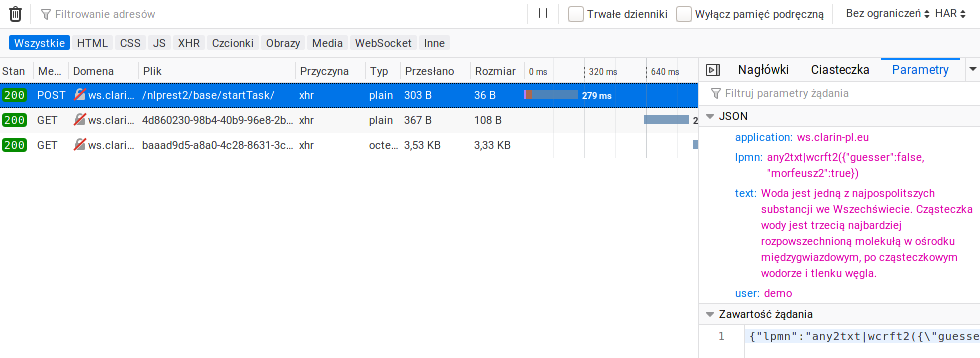
As with any API provided to the public, you should notify the provider about your intentions and remember about some sane throttling of requests. Moreover, it's considered good manners to set the user parameter to something meaningful (like email address).
Conclusions
We went through the basic steps of analyzing a corpus and touched on more advanced topics, like morphological analysis and lemmatization. If you're doing a quick and dirty analysis, outsourcing those basic tasks to ready tools and APIs sounds like the best option. In case you need to run a large scale experiments, it makes more sense to run the tools on your own hardware. The lemmatized text might become a powerful input to a more sophisticated models, like recurrent neural networks.
Citations
- [1] http://grzegorz.jagodzinski.prv.pl: Polish grammar rules
- [2] Wikpedia: Polish grammar
- [3] Quora: how many words are the in the Polish language
You're my type: Python, meet static typing
(originally published: 2020-09-19)
- The why
- The how
- The wow
- How do you introduce types in your codebase?
- Most popular Python type checkers, compared
- Third-party libraries
- Outro
If you’re writing Python code in a production environment, it’s quite likely that you have been using type hints or static type checking. Why do we need these tools? How can you use them when you’re developing your own project? I hope to answer these questions in this blogpost.
The why
Python was designed as a dynamically typed language - the developer should be able to solve the problems quickly, iterating quickly in the interactive REPL. The type system will work things out transparently for the developer.
def checkConstraintsList2(solution, data):
"""
This is an actual excerpt from a BEng thesis, python2 style.
Trying to infer the data types is painful, so is debugging or
extending this snippet.
:param solution:
:param data:
"""
for slot in range(0, data.periodsPerDay * data.daysNum):
for lecture in solution[slot]:
for constraint in data.getConstraintsForCourse(lecture[0]):
if slot == solution.mapKeys(constraint):
print "Violation lecture", lecture, "slot", slot
Ugly Python2-style snippet from an ML project. Non-trivial data-structures make reading this a horrible experience.
This approach works great for tiny, non-critical codebases, with a limited number of developers. Since even Google was at some point in time a tiny, non-critical codebase I’d advise you not to follow this path.
The how
PEP484 added type comments as a standardized way of adding type information to Python code.
def weather(celsius): # type: (Optional[float]) -> Union[str, Dict[str, str]]
if celsius is None:
return "I don’t know what to say"
return (
"It’s rather warm"
if celsius > 20 else {"opinion": "Bring back summer :/"}
)
The separation of the identifier and type hint makes it hard to read.
This used to be the only way to add types to Python codebase until Python 3.6 got released, adding optional type hints to it’s grammar:
from typing import Dict, Optional, Union
def weather(celsius: Optional[float]) -> Union[str, Dict[str, str]]:
if celsius is None:
return "I don’t know what to say"
return (
"It’s rather warm"
if celsius > 21 else {"opinion": "Bring back summer :/"}
)
Much better. Please note - this code example introduced some additional import statements. These are not free, since Python interpreter needs to load code for that import, resulting in some barely noticeable overhead, depending on your codebase.
If you’re looking to speed up your code, Cython uses a slightly altered Python syntax of type annotations for compiling to machine code in for the sake of the speed.
The wow
The type hints might be helpful for the developer, but humans commit errors all the time - you should definitely use a type checker to validate if your assumptions are correct. (And, catch some bugs before they hit you!)
How do you introduce types in your codebase?
Most type checkers follow the approach of gradual introduction of enforcement of type correctness. The type checkers can infer the types of the variables or return types to some degree, but in this approach it’s the developers responsibility to gradually increase the coverage of strict type checking, usually module by module.
Additionally, you can control either particular features of the type system being enforced (e.g. forbidding redefinition of a variable with a different type) or select one of the predefined strictness levels. The main issue is that it involves manual process - you need to define the order or modules in which you want to annotate your codebase and, well, manually do it.
Pytype follows a completely different approach - it type checks the entire codebase by default, instead taking a very permissive take on type correctness - if it’s valid Python, it’s OK. This approach definitely makes sense in application to older or unmaintained projects with minimal or no type hints since it allows you to catch the basic type errors very quickly, with no changes made to the codebase. This sounds very tempting, but the long term solution should be to apply more strict type checking. Valid Python’s type system is just way too permissive.
Most popular Python type checkers, compared
| Mypy | pytype | Pyright | [Pyre](https://github.com/facebook/pyre-check | |
|---|---|---|---|---|
| Modes | Feature flags for strictness checks | Lenient: if it runs, it’s valid | Multiple levels of strictness enforced per project and directory | Permissive / strict modes |
| Applying to existing code | Gradual | Runs on entire codebase, type hints completely optional | Gradual | Gradual |
| Implementation | Daemon mode, incremental updates | set of CLI tools | Typescript, daemon mode, incremental updates | Daemon mode with watchman, incremental updates |
| IDE integration | Incomplete LSP plugin | maybe someday | LSP, Pylance vscode extension, vim | VSCode, vim, emacs |
| Extra points | Guido-approved | Merge-pyi automatically merges type stubs into your codebase | Snappy vscode integration, no Python required - runs on node js | Built in Pysa - static security analysis tool |
Third-party libraries
Not all libraries you use are type annotated - that’s a sad fact. There are two solutions to this problem - either just annotate them, or use type stubs. If you’re using a library, you care only about the exported data structures and function signature types. Some typecheckers utilize an official collection of type annotations maintained as a part of Python project - Typeshed (see example type stubs file). If you find a project that doesn’t have type hints, you can contribute your annotations to that repo, for the benefit of everyone!
class TcpWSGIServer(BaseWSGIServer):
def bind_server_socket(self) -> None: ...
def getsockname(self) -> Tuple[str, Tuple[str, int]]: ...
def set_socket_options(self, conn: SocketType) -> None: ...
The ... is an Ellipsis object. Since it's builtin constant, the code above is valid Python, albeit useless (besides being type stub).
Some static type checkers create pyi stubs behind the scenes. Pytype allows you to combine the inferred type stubs with the code using a single command. This is really neat - you can seed the initial types in your code with a single command - although the quality of the annotations is quite weak, since Pytype is a lenient tool, you will see Any wildcard type a lot. Type hints: beyond static type checking
The type-correctness is not the only use case of the type hints. Here you can find some neat projects making good use of type annotations:
Pydantic
Pydantic allows you to specify and validate your data model using intuitive type-annotated classes. It’s super fast and is a foundation of FastAPI web framework (request/response models and validations).
from typing import List, Optional
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
tax: Optional[float] = None
tags: List[str] = []
@app.post("/items/", response_model=Item)
async def create_item(item: Item):
return item
You get request and response validation for free.
Typer
Generating CLIs using just type-annotated functions. Typer takes care of parsing, validating and generating boilerplate for you.
Hypothesis
Hypothesis is a library enabling property-based testing for pytest. Instead of crafting custom unit test examples, you specify functions generating the test cases for you. Or… you can use inferred strategies which will sample the space of all valid values for a given type!
from hypothesis import given, infer
@given(username=infer, article_id=infer, comment=infer)
def test_adding_comment(username: str, article_id: int, comment: str):
with mock_article(article_id):
comment_id = add_comment(username, comment)
assert comment_id is not None
Inferred strategies are a good start, but you should limit the search space of your examples to match your assumptions (would you expect your article_ids to be negative?)
Outro
Static type checking gives the developers additional layer of validation of their code against the common type errors. With the wonders of static analysis, you can significantly reduce the number of bugs, make contributing to the code easier and catch some non-trivial security issues.

Thanks