Getting started with Natural Language Processing in Polish
There are countless tutorials on how to do NLP on the internet. Why would you care to read another one? Well, we will be looking into analysing Polish language, which is still rather underdeveloped in comparison to English.
Polish language is much more complex when compared to English language, as it contains 7 cases (deklinacja), 3 kinds (masculine, femenine, unspecified) and 11 different templates of verb conjugation, not to mention the exceptions [1] [2] [3]. English is rather simple: verb conjugation is easy, nouns pluralise easily, there are hardly any genders.
Corpus
For the sake of this analysis, we will look at collection of articles obtained (the nice word for scraped) from one of the leading right-wing news websites, wpolityce.pl.
 Sample article from the dataset.
Sample article from the dataset.
The articles were collected over a period of 15 days ending 10th June 2019, only articles linked from front page were collected. In total there are 1453 unique articles. I shall later publish my insights on collecting datasets from the wild.
Tokenizing
Tokens are the smallest unit of the language that's most commonly taken into account when doing text analysis. You may think of it as a word, which in most cases it is. Things get trickier in English with it's abbreviations like I'd or we've but Polish is much easier in this aspect.
„|Gazeta|Wyborcza|”|wielokrotnie|na| |swoich|łamach|wspierała|działania|Fundacji|Nie|lękajcie|się|Marka|Lisińskiego|.
Sample tokenization of a sentence from the corpus, tokens are delimited with vertical bars. Please note empty token between words na and swoich - it's a dirty whitespace, which we'll deal with shortly.
In Python, you can tokenize using either NLTK's nltk.tokenize package or spaCy's tokenizer using pretrained language models. I have used the latter with xx_ent_wiki_sm multilanguage model. In empirical analysis it appeared to split up the tokens in a plausible manner.
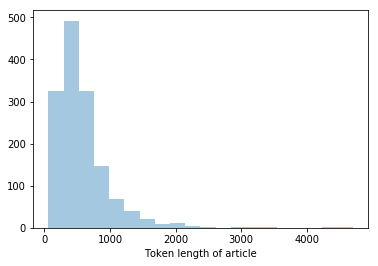
The distribution of numbers of tokens in an article: vertical axis shows number of articles falling into particular bucket, horizontal axis is the token lenght of article.
Quantitative analysis: corpus
Reading the entire dataset without any cleaning yields mediocre results. The resulting corpus contains:
- badly interpreted non-breaking space from latin1 encoding (
"\xa0") - whitespace-only tokens (
"\n","\n \n"and others) - punctuation, also in repeated non-ambiguous way (multiple quote chars, hyphen/minus used interchangeably)
- stopwords: common words that skew the word distribution but do not bring any value to the analysis.
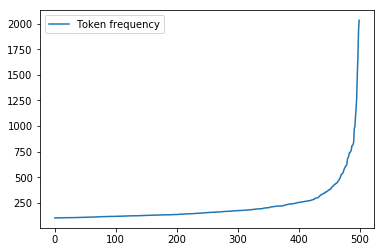
Frequent words (unigrams)
| word | frequency |
|---|---|
| PiS | 1444 |
| proc | 1198 |
| wyborach | 835 |
| powiedział | 726 |
| PAP | 709 |
| PSL | 676 |
| r. | 653 |
| Polski | 652 |
| Polsce | 625 |
| Europejskiej | 601 |
Word cloud
The raw data above can be visualised using a word cloud. The idea is to represent the frequency of the word with it's relative size on the visualisation, framing it in visually attractive and appealing way.
You can find plenty of online generators that will easily let you tweak the shape, colors and fonts. Check out my wordcloud of 50 most common words from the corpus generated using generator from worditout.com

Concluding our unigram analysis, the most common topics were revolving around PiS (abbreviation used by the polish ruling party), elections (wyborach stands for elections, proc. is abbreviated percent).
Ngrams
Ngram is just a sequence of n consecutive tokens. For n=2 we also use word bigram. You can get the most frequent Ngrams (sequences of words of particilar length) using either nltk.ngrams or trivial custom code. For length 2-3 you are highly likely to fetch popular full names. Longer ngrams are likely to catch parts of frequently repeated sentences, like promos, ads and references.
Bigrams
As expected, we are catching frequent proper names of entities in the text. Below is a breakdown of 10 most frequent bigrams from the corpus:
| frequency | bigram | interpretation |
|---|---|---|
| 377 | Koalicji Europejskiej | political party |
| 348 | Parlamentu Europejskiego | name of institution |
| 322 | PAP EOT | source/author alias |
| 261 | 4 czerwca | important date discussed at the time |
| 223 | Koalicja Europejska | political party |
| 136 | Andrzej Duda | full name of President of Poland |
| 126 | Jarosław Kaczyński | full name of important politician |
| 126 | Jana Pawła | most likely: prefix from John Paul II |
| 125 | Pawła II | most likely: suffix from John Paul II |
Sixgrams
Longer ngrams expose frequent phrases used throughout the corpus. Polish has a lot of cases and persons, so this method is not of much help to find frequent phrases in the language itself; you are more likely to find repeated parts of sentences or adverts.
| frequency | sixgram |
|---|---|
| 61 | Kup nasze pismo w kiosku lub |
| 61 | nasze pismo w kiosku lub skorzystaj |
| 61 | pismo w kiosku lub skorzystaj z |
| 61 | w kiosku lub skorzystaj z bardzo |
| 61 | kiosku lub skorzystaj z bardzo wygodnej |
Clearly, there is an issue here. While doing our quantitative analysis our distributions and counts are skewed by the advert texts being present in most of the articles. Ideally we should factor these phrases out of our corpus, either at a stage of data collection (improving the parser to annotate/omit these phrase) or data preprocessing (something we're doing in this article).
Much better idea is to perform ngrams analysis on lemmatized text. This way you may mine more knowledge about the language, not just repeated phrases.
Morphological analysis
In the previous paragraph we saw that the different forms of the words will make learning about the language harder - we are capturing the information about the entire word, with the particular gender, tense and case. This becomes particularly disruptive in Polish.
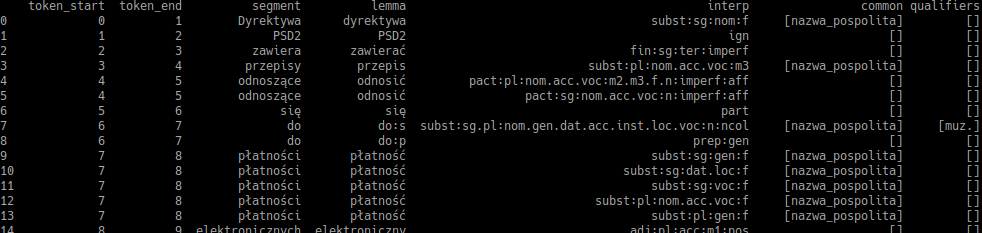
One potential solution is called morphological analysis. This is a process of mapping a word to all of it's potential dictionary base words (lexems). Sample lemmatization:
| Original word | Lemma tag | Lexem |
|---|---|---|
| Dyrektywa | dyrektywa | subst:sg:nom:f |
| PSD2 | PSD2 | ign |
| zawiera | zawierać | fin:sg:ter:imperf |
| przepisy | przepis | subst:pl:nom:m3 |
| odnoszące | odnosić | pact:sg:nom:n:imperf:aff |
| się | się | qub |
| do | do | prep:gen |
| płatności | płatność | subst:sg:gen:f |
| elektronicznych | elektroniczny | adj:pl:gen:m1:pos |
| realizowanych | realizować | ppas:pl:gen:m1:imperf:aff |
| wewnątrz | wewnątrz | adv:pos |
| Unii | unia | subst:sg:gen:f |
| Europejskiej | europejski | adj:sg:gen:f:pos |
| . | . | interp |
We will not be implementing this part from scratch, instead we can use resources from IPI PAN (Polish Academy of Science), specifically a tool called Morfeusz.
Morfeusz is a morphosyntactic analyzer which you can use to find all word lexems and the forms. The output will be slightly different than the table above: instead, for every input word Morfeusz will output all of it's possible dictionary forms.
Usage
I assume you are running either a recent Ubuntu or Fedora. After fetching the right version from Morfeusz download page do the following:
tar xzfv <path to archive>
sudo cp morfeusz/lib/libmorfeusz2.so /usr/lib/local
sudo chmod a+x /usr/lib/local/libmorfeusz2.so
sudo echo "/usr/local/lib" > /etc/ld.so.conf.d/local.conf
sudo ldconfig
Now we can download and install the python egg from morfeusz download page.
easy_install <path_to_downloaded_egg>
The best thing about the python package is that you can retrieve the result from the analyzer using just a couple of python lines:
import morfeusz2
m = morfeusz2.Morfeusz()
result = m.analyze("Ala ma kota, kot ma Alę.")
# the result is:
[(0, 1, ('Dyrektywa', 'dyrektywa', 'subst:sg:nom:f', ['nazwa_pospolita'], [])),
(1, 2, ('PSD2', 'PSD2', 'ign', [], [])),
(2, 3, ('zawiera', 'zawierać', 'fin:sg:ter:imperf', [], [])),
(3,
4,
('przepisy', 'przepis', 'subst:pl:nom.acc.voc:m3', ['nazwa_pospolita'], [])),
(4,
5,
('odnoszące',
'odnosić',
'pact:pl:nom.acc.voc:m2.m3.f.n:imperf:aff',
[],
[])),
(4, 5, ('odnoszące', 'odnosić', 'pact:sg:nom.acc.voc:n:imperf:aff', [], [])),
Putting it all in a pandas DataFrame is a trivial task as well:
import pandas as pd
colnames = ["token_start", "token_end", "segment", "lemma", "interp", "common", "qualifiers"]
df = pd.DataFrame.from_records([(elem[0], elem[1], *elem[2]) for elem in result], columns=colnames)
Helpful links on tackling Morfeusz:
Lemmatization
You have already seen the output of a lemmatizer at the beginning of previous section. In contrast to Morfeusz's output, this time we want to obtain a mapping for each word to it's most probable dictionary form.
In order to obtain direct tags instead of list of tags for each token, you will need to go deep into morphological taggers land. Your options are:
- WCRFT - actually having a working demo here. Requires some skill to get it to work, dependencies are non-trivial to put together,
- PANTERA - doesn't appear to be actively maintained
- Concraft - implemented in Haskell, looks to be the easiest one to get running
If you are just doing a casual analysis of text, you may want to consider outsourcing the whole tagging process to a RESTful API, like http://nlp.pwr.wroc.pl/redmine/projects/nlprest2/wiki/Asynapi.
You can easily reverse-engineer the exact calls to the API using Firefox/Chrome dev tools. This way you can find the correct values for the parameters.
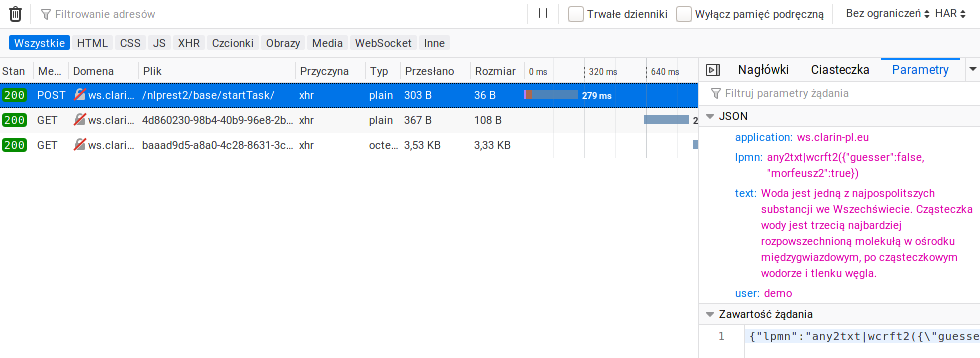
As with any API provided to the public, you should notify the provider about your intentions and remember about some sane throttling of requests. Moreover, it's considered good manners to set the user parameter to something meaningful (like email address).
Conclusions
We went through the basic steps of analyzing a corpus and touched on more advanced topics, like morphological analysis and lemmatization. If you're doing a quick and dirty analysis, outsourcing those basic tasks to ready tools and APIs sounds like the best option. In case you need to run a large scale experiments, it makes more sense to run the tools on your own hardware. The lemmatized text might become a powerful input to a more sophisticated models, like recurrent neural networks.